Databricks Partition Performance. this article explains how to trigger partition pruning in delta lake merge into (aws | azure | gcp) queries from databricks. this article provides an overview of how you can partition tables on databricks and specific recommendations around when you should. job monitoring provides insights into job performance, enabling you to optimize resource utilization, reduce wastage, and improve. delta lake liquid clustering replaces table partitioning and zorder to simplify data layout decisions and optimize query performance. Delta lake provides acid transactions, scalable metadata handling, and unifies streaming and batch data processing. the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that. Delta lake runs on top of your existing data lake and is fully compatible with apache spark apis. based on the posted request rate guidelines for s3, it seems like increasing the number of partitions (key prefixes) should. partition pruning — the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that the.
from codelabs.developers.google.com
based on the posted request rate guidelines for s3, it seems like increasing the number of partitions (key prefixes) should. job monitoring provides insights into job performance, enabling you to optimize resource utilization, reduce wastage, and improve. Delta lake provides acid transactions, scalable metadata handling, and unifies streaming and batch data processing. the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that. delta lake liquid clustering replaces table partitioning and zorder to simplify data layout decisions and optimize query performance. partition pruning — the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that the. this article provides an overview of how you can partition tables on databricks and specific recommendations around when you should. Delta lake runs on top of your existing data lake and is fully compatible with apache spark apis. this article explains how to trigger partition pruning in delta lake merge into (aws | azure | gcp) queries from databricks.
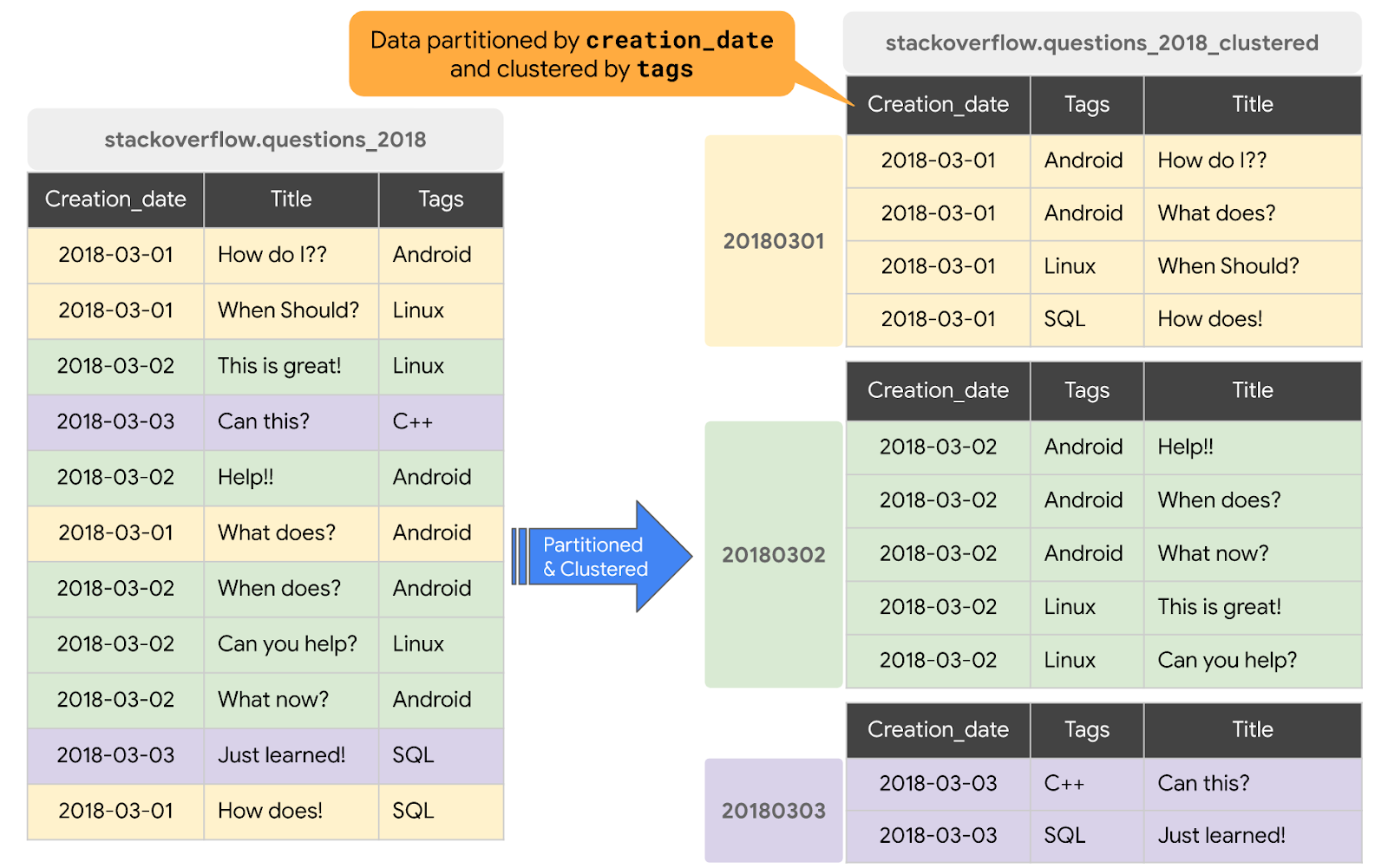
Partitioning and Clustering in BigQuery Google Codelabs
Databricks Partition Performance the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that. Delta lake runs on top of your existing data lake and is fully compatible with apache spark apis. this article provides an overview of how you can partition tables on databricks and specific recommendations around when you should. partition pruning — the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that the. this article explains how to trigger partition pruning in delta lake merge into (aws | azure | gcp) queries from databricks. delta lake liquid clustering replaces table partitioning and zorder to simplify data layout decisions and optimize query performance. based on the posted request rate guidelines for s3, it seems like increasing the number of partitions (key prefixes) should. the partition elimination technique allows optimizing performance when reading folders from the corresponding file system so that. Delta lake provides acid transactions, scalable metadata handling, and unifies streaming and batch data processing. job monitoring provides insights into job performance, enabling you to optimize resource utilization, reduce wastage, and improve.